본 포스팅은 [파이썬 머신러닝 완벽 가이드 - 권철민]을 참고하여 머신러닝 공부의 목적으로 작성되었습니다!
[스스로 공부하며 작성하는 글이기 때문에 잘못된 내용이 있을 수도 있습니다. 잘못된 부분을 발견하시거나 의견이 있으시면 피드백 부탁드립니다:D]
- 넘파이(Numpy) 개요 - array,shape,dtype
넘파이는 파이썬에서 선형대수 기반의 프로그램을 쉽게 만들 수 있도록 지원하는 대표적인 패키지입니다.
많은 머신러닝 알고리즘이 넘파이 기반으로 작성되어 있기 때문에 넘파이를 이해하는 것은 파이썬 기반의 머신러닝에서 매우 중요하다고 합니다.
넘파이의 기본 데이터 타입은 ndarray로, 다차원 배열을 쉽게 생성하여 다양한 연산을 수행할 수 있도록 합니다.
넘파이의 array()함수를 이용하면 원하는 인자를 ndarray 타입으로 변환해줍니다.
먼저 numpy모듈을 임포트하고 적용해봅니다.

리스트 형태의 값을 array() 함수를 이용하여 ndarray로 바꿔주었습니다.
여기서 shape 변수를 짚고 넘어가 보겠습니다.
shape변수는 ndarray의 크기, 즉 행과 열의 수를 를 튜플 형태로 나타냅니다. 여기서 튜플 요소의 개수는 ndarray 배열의 차원이라 할 수 있습니다.
위의 array1은 튜플 안 요소가 3 하나이므로 array1은 1차원의 배열이며 3개의 데이터를 가지고 있음을 알 수 있습니다.
예제를 보며 조금 더 살펴보겠습니다.

array2를 보면 shape이 (2,3)으로 튜플 안 요소가 2,3 총 2개입니다. 따라서 array2는 2차원 배열이고 2개의 로우와 3개의 칼럼으로 이루어진 배열임을 알 수 있습니다.
array3는 앞서 본 array1과 비슷해 보이지만 엄연히 다른 배열입니다. shape를 보면 (1,3)으로 튜플 안 요소가 총 2개, 2차원 배열이며 1개의 로우와 3개의 칼럼으로 이루어진 배열입니다.
array의 차원을 ndarray.ndim을 이용해 확인해보겠습니다.

넘파이 내의 데이터 타입은 같은 데이터 타입만 가능합니다. 만약 다른 데이터 유형이 섞여있는 리스트를 ndarray로 변환하면 데이터 크기가 더 큰 데이터 타입으로 자동 형 변환됩니다.

int형과 float형이 섞여있던 list를 ndarray로 변환했더니 데이터 타입이 float으로 변경되었습니다. [4(int) < 8(float)]
astype()함수를 이용하여 array_type의 데이터 타입을 다시 int로 바꿔보도록 하겠습니다.

- arange(), zeros(), ones()
-arange(start, stop, step)
: start부터 (stop-1)까지 값을 순차적으로 ndarray의 데이터 값으로 변환해줍니다. start와 step 값을 지정해주지 않으면 0부터 시작하여 (stop-1)까지 1씩 증가하는 연속적인 숫자로 구성된 1차원 ndarray가 반환됩니다.

-zeros(shape, dtype)
: 함수 인자로 튜플 형태의 shape를 입력하면 모든 값을 0으로 채운 해당 shape를 가진 ndarray를 반환합니다.
dtype은 지정해주지 않으면 default값으로 float64형의 데이터로 ndarray를 채웁니다.
-ones(shape, dtype)
: zeros와 비슷하지만 모든 값을 1로 채운다는 점이 zeros와 다릅니다.

- reshape()
원하는 크기를 함수 인자로 입력해주면 ndarray를 특정 차원 및 크기로 변환해줍니다.

여기서 주의할 것은 reshape()는 지정된 사이즈로 변경이 불가능하면 오류를 발생시킨다는 것입니다.
위의 예제에서 array는 0~9이므로 10개의 데이터로 이루어져 있습니다. 따라서 10의 약수인 2와 5를 이용하여 행, 열 조합으로 array를 변환할 수 있었습니다.
하지만 array를 (4,3)의 shape로 변환하려 하면 4*3=12개의 데이터가 필요한데 array는 10개의 데이터로 이루어져 있으므로 변환 불가능합니다.
-1을 인자로 사용하면 호환 가능한 새로운 shape으로 쉽게 변환 가능합니다. 예시를 통해 확인해보겠습니다.

지정해준 행, 열 개수를 고려하여 -1이었던 자리가 데이터 개수(10)에 맞게 5로 바뀐 것을 알 수 있습니다.
하지만 이 경우에도 array.reshape(-1,4)처럼 호환 불가능한 형태로는 변환될 수 없습니다.

- 인덱싱(Indexing)
넘파이에서 ndarray 내의 일부 데이터 세트나 특정 데이터만을 선택할 수 있습니다. 이를 인덱싱이라고 합니다.
인덱싱의 종류에는 4가지가 있습니다.
1. 단일 값 추출
-한 개의 데이터만을 추출할 때 사용합니다. [ ] 안에 원하는 값의 인덱스를 넣어 추출할 수 있습니다.

앞서 보았던 arange를 이용해 1부터 9까지의 ndarray를 생성하고 array의 3번째 요소인 3을 추출해보았습니다.
(start값을 1로 지정해주었더니 0(default 값)이 아닌 1부터 시작했음을 알 수 있습니다.)
여기서 주의할 것은 인덱스가 1이 아닌 0부터 시작한다는 것입니다. 따라서 값 3의 인덱스는 2가 됩니다.
또한 ndarray에서 추출한 데이터 값(단일 값) array [2]의 데이터 타입은 더 이상 ndarray가 아닙니다.
2. 슬라이싱
-연속한 데이터 세트를 추출하는 것을 슬라이싱이라 합니다. 추출된 데이터 세트는 ndarray 타입입니다.
[ ] 안에 원하는 인덱스의 범위를 ':'기호를 이용하여 넣어줍니다. 시작 인덱스부터 (종료 인덱스-1)까지의 값을 반환합니다.

이때 ':' 사이의 시작, 종료 인덱스는 생략이 가능한데
시작 인덱스를 생략하면 맨 처음부터,
종료 인덱스를 생략하면 맨 끝까지,
둘 다 생략하면 모든 범위의 데이터를 추출합니다.

같은 방식으로 2차원 데이터의 슬라이싱은 밑의 예제를 보시면 이해가 쉬우실 겁니다.

3. 팬시 인덱싱
-[ ] 안에 리스트나 ndarray로 인덱스 집합을 지정하여 데이터 값을 추출하는 방식입니다. 슬라이싱이 ':'기호를 이용해 연속적인 행이나 열의 값을 추출했다면 팬시 인덱싱은 불연속적인 행, 열 위치의 데이터 값을 반환할 수 있습니다.

4. 불린 인덱싱
-불린 인덱싱은 인덱스를 지정하는 [ ] 안에 조건문을 넣어줌으로써 원하는 조건을 만족하는 값들을 추출하는 방식입니다. for loop나 if else문을 이용하지 않고도 간단하게 데이터를 추출할 수 있습니다.

그렇다면 불린 인덱싱이 어떻게 동작하는지 알아보겠습니다.

조건을 입력했을 때 조건에 해당하는 값들은 True, 그렇지 않은 값들은 False가 됩니다.
이후 False 값들은 무시하고 True 값에 해당하는 Index 값만 저장하여 새로운 index를 만들고 [5,6,7,8,9]
그 index를 이용하여 데이터를 추출합니다. array1 d[[5,6,7,8,9]]=[5,6,7,8,9]
- 행렬의 정렬- sort()와 argsort()
1.sort()
1) np.sort(배열 이름)과 같이 넘파이에서 sort() 호출하기
-정렬된 행렬을 반환하지만 원 행렬은 바뀌지 않습니다.
2. 배열 이름. sort()
-반환 값은 없지만(None이지만) 원 행렬 자체를 정렬하여 바꿔줍니다.

np.sort(배열 이름)이나 배열 이름. sort()는 모두 기본적으로 오름차순으로 정렬하기 때문에 내림차순을 해주려면 뒤에 [::-1]을 추가하면 됩니다.

여기서 행렬이 2차원 이상일 경우의 정렬 방법에 대해 알아보겠습니다.
이 전에 먼저 axis에 대해 알아야 합니다. 2차원 배열을 가지고 알아보겠습니다.
- axis

axis는 축이라는 뜻입니다.
그림과 같이 axis0은 로우 방향의 축을 의미하고 axis1은 칼럼 방향의 축을 의미합니다.
사실 넘파이 ndarray에서는 로우, 칼럼 방식을 사용하지 않으나 그저 이해를 쉽게 하기 위해 표현한 것입니다.
따라서 [row=0, col=1]인 인덱싱은 정확히 표현하면 [axis0=0, axis1=1]입니다.
(+3차원 ndarray의 경우 axis0 = 행, axis1 = 열, axis2 = 높이입니다.)
이러한 axis를 이용하여 다차원 배열에서 정렬을 수행할 수 있습니다.

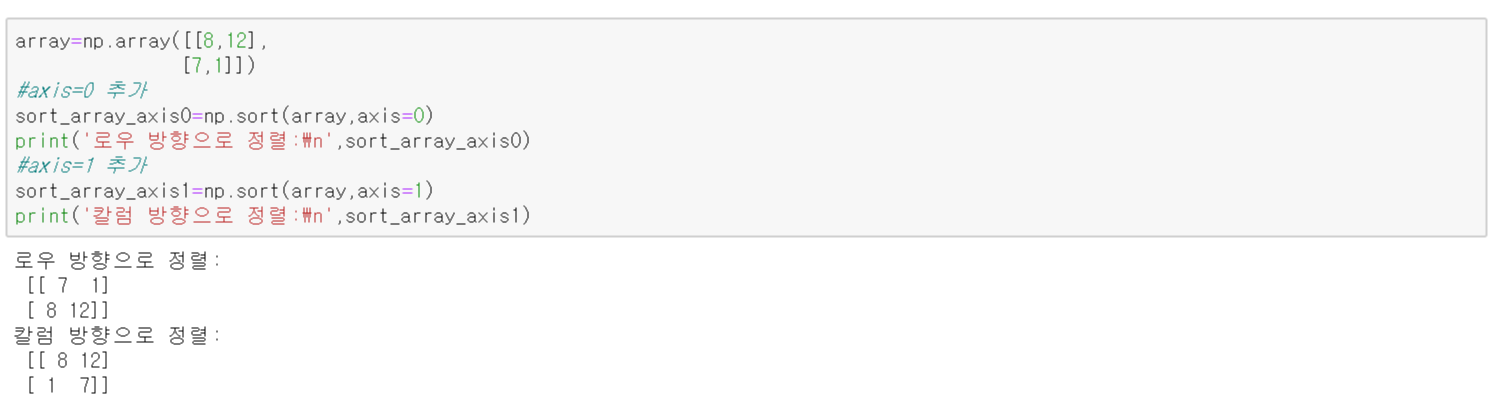
axis=0으로 설정하였더니 로우 방향을 기준으로 하여 정렬된 것을 볼 수 있습니다. 8과 7, 12와 1을 비교했을 때 각각 7과 1 이 더 작으므로 데이터들의 순서가 바뀐 것을 볼 수 있습니다.
마찬가지로 axis=1일 때는 칼럼 방향을 기준으로 정렬되었습니다.
코드는 다음과 같습니다.
2.argsort()
-sort()가 행렬을 정렬하는 것이었다면 argsort()는 행렬이 정렬됨에 따라 바뀐 원본 행렬의 index값을 ndarray 형으로 반환합니다.


argsort를 통해 반환된 index를 다시 array의 index값으로 넣어주면 정렬된 array를 얻을 수 있습니다.
(추출하고자 하는 데이터의 인덱스 값을 리스트나 ndarray의 형태로 넣어주는 팬시 인덱싱과 같아지기 때문입니다.
=> original_array[[1,0,3,2]] )

argsort를 이용하여 성적이 높은 순으로 학생들의 이름을 출력하는 예제를 살펴보겠습니다.

- 선형대수 연산 - 행렬 내적, 전치 행렬
1. 행렬 내적
-행렬 내적은 행렬의 곱입니다. 간단하게 np.dot(A, B)를 이용하여 행렬 A와 행렬 B의 곱을 구할 수 있습니다.
이때 주의해야 할 것은 행렬 곱은 A의 열 개수의 B의 행 개수가 같아야 가능하다는 것입니다.
( ex : A [3 X 5] [5 X 4] B 5로 같으므로 가능!
A [3 X 4] [6 X 4] B 같이 않으므로 불가능! )


2. 전치 행렬
-원 행렬에서 행과 열의 위치를 바꾼 행렬을 전치 행렬이라 합니다. np.transpose()를 이용하여 쉽게 구할 수 있습니다.


지금까지 넘파이(Numpy)에 대해 알아보았습니다.
다음 포스팅에서는 대표적인 데이터 핸들링 프레임워크인 판다스(Pandas)에 대해 알아보도록 하겠습니다.
[참고 자료 출처 : https://tech.choiyedam.com/python-numpy-basic2/ ]
'파이썬 머신러닝 완벽가이드' 카테고리의 다른 글
| 2강 - 사이킷런으로 시작하는 머신러닝 (2) (0) | 2020.09.08 |
|---|---|
| 2강 - 사이킷런으로 시작하는 머신러닝(1) (0) | 2020.09.02 |
| 1강-Pandas(2) (0) | 2020.08.26 |
| 1강-Pandas (1) (2) | 2020.08.19 |



